Теория баз данных
Файлы с неплотным индексом, или индексно-последовательные файлы
Попробуем усовершенствовать способ хранения файла: будем хранить его в упорядоченном виде и применим алгоритм двоичного поиска для доступа к произвольной записи. Тогда время доступа к произвольной записи будет существенно меньше. Для нашего примера это будет:
Т = log2KBO = log212500 = 14 обращений к диску.
И это существенно меньше, чем 12 500 обращений при произвольном хранении записей файла. Однако и поддержание основного файла в упорядоченном виде также операция сложная.
Неплотный индекс строится именно для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов имеет следующий вид:
|
Значение ключа первом записи блока |
Номер блока с этой записью |
||
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области. На рис. 9.8 представлен пример заполнения основной и индексной областей, если первичным ключом являются целые числа.
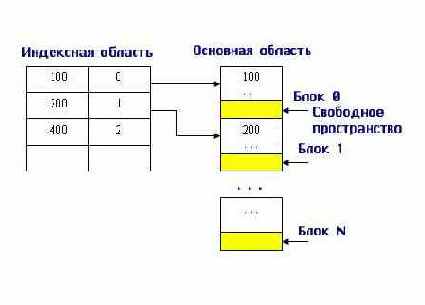
Рис. 9.8. Пример заполнения индексной и основной области при организации неплотного индекса
Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше. Оценим время доступа к произвольной записи для файлов с неплотным индексом. Алгоритм решения задачи аналогичен.
Сначала определим размер индексной записи. Если ранее ссылка рассчитывалась исходя из того, что требовалось ссылаться на 100000 записей, то теперь нам требуется ссылаться всего на 12 500 блоков, поэтому для ссылки достаточно двух байт. Тогда длина индексной записи будет равна:
LI = LK + 2 = 14 + 2 - 14 байт.
Тогда количество индексных записей в одном блоке будет равно:
KIZB = LB/LI = 1024/14 = 73 индексные записи в одном блоке.
Определим количество индексных блоков, которое необходимо для хранения требуемых индексных записей:
KIB = KBO/KZIB = 12500/73 = 172 блока.
Тогда время доступа по прежней формуле будет определяться:
Тпоиска = log2KIB + 1 = log2172 + 1=8+1=9 обращений к диску.
Мы видим, что при переходе к неплотному индексу время доступа уменьшилось практически в полтора раза. Поэтому можно признать, что организация неплотного индекса дает выигрыш в скорости доступа.
Рассмотрим процедуры добавления и удаления новой записи при подобном индексе.
Здесь механизм включения новой записи принципиально отличен от ранее рассмотренного. Здесь новая запись должна заноситься сразу в требуемый блок на требуемое место, которое определяется заданным принципом упорядоченности на множестве значений первичного ключа. Поэтому сначала ищется требуемый блок основной памяти, в который надо поместить новую запись, а потом этот блок считывается, затем в оперативной памяти корректируется содержимое блока и он снова записывается на диск на старое место. Здесь, так же как и в первом случае, должен быть задан процент первоначального заполнения блоков, но только применительно к основной области. В MS SQL server этот процент называется Full-factor и используется при формировании кластеризованных индексов. Кластеризованными называются как раз индексы, в которых исходные записи физически упорядочены по значениям первичного ключа. При внесении новой записи индексная область не корректируется.
Количество обращений к диску при добавлении новой записи равно количеству обращений, необходимых для поиска соответствующего блока плюс одно обращение, которое требуется для занесения измененного блока на старое место.
Тдобавлений = log2N +1 + 1 обращений.
Уничтожение записи происходит путем ее физического удаления из основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока. Поэтому количество обращений к диску при удалении записи такое же, как и при добавлении новой записи.